Build real security skills with AppSecEngineer—50% off sitewide with code 'NOEXCUSES50'.
.svg)
Build real security skills with AppSecEngineer—50% off sitewide with code 'NOEXCUSES50'.

Have you ever wondered why an AI made a specific decision? You're not alone. Large Language Models (LLMs) like GPT-4 and Llama have completely changed how we interact with technology, but their impressive capabilities come with a major catch: they're often a black box. This lack of transparency makes it incredibly difficult to understand and trust their outputs, especially in high-stakes fields like medicine or finance.
LLMs complexity and sheer scale make it difficult to know why a certain output was generated or how a conclusion was reached. This lack of transparency can hide:

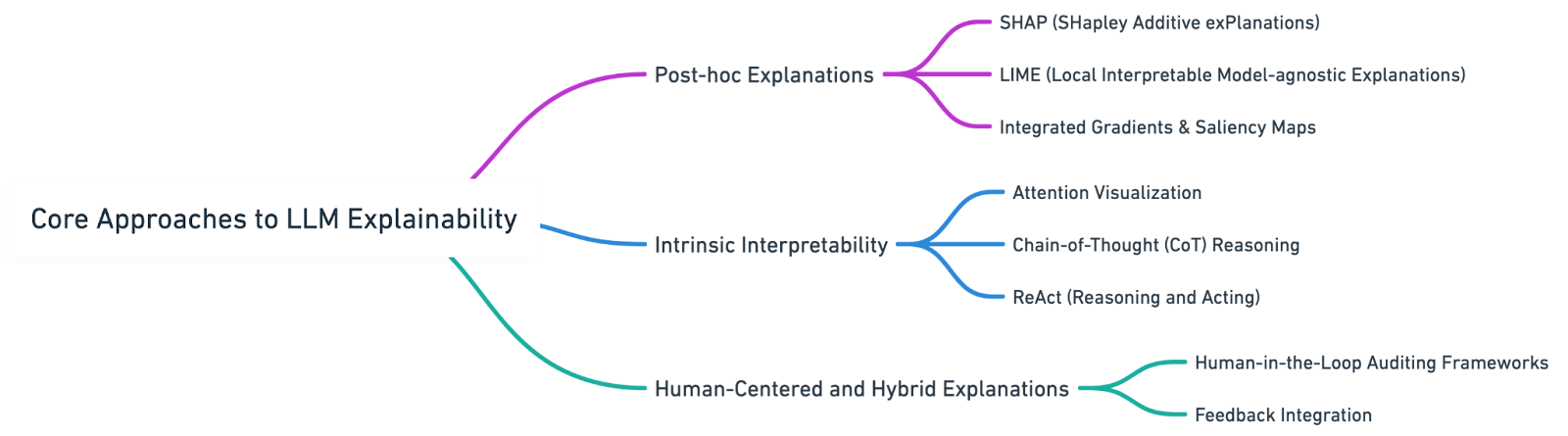
These methods explain a model’s decisions after-the-fact, without modifying the model’s architecture.
If an LLM predicts that a financial document contains fraudulent activity, LIME/SHAP can point to specific phrases or numbers in the text that “tipped the scale.”
Designing models that are more explainable by architecture or through enforced reasoning steps.
In medical diagnosis, CoT-enabled LLMs would explain decisions sequentially—first symptoms, then history, finally risk evaluation—each step exposed and auditable.
Bringing human feedback into the loop, ensuring explanations are actionable and understandable.
Relying solely on automated tools to audit LLMs misses critical nuances. Human feedback loops provide the contextual judgment that machines can’t replicate… yet. Effective LLM auditing requires human reviewers to not only validate model behavior but to shape it over time. Regular explainability audits should integrate three pillars:
By involving subject-matter experts, such as clinicians in healthcare, legal professionals in compliance-heavy applications, financial analysts in fintech, you improve both the technical fidelity and social acceptability of your model’s outputs.
Teams should build feedback ingestion pipelines that route reviewer insights back into model refinement cycles. This can include RLHF (Reinforcement Learning from Human Feedback), structured annotation workflows, and feedback scoring systems that influence fine-tuning datasets. Without this loop, model updates risk repeating or even amplifying flaws.
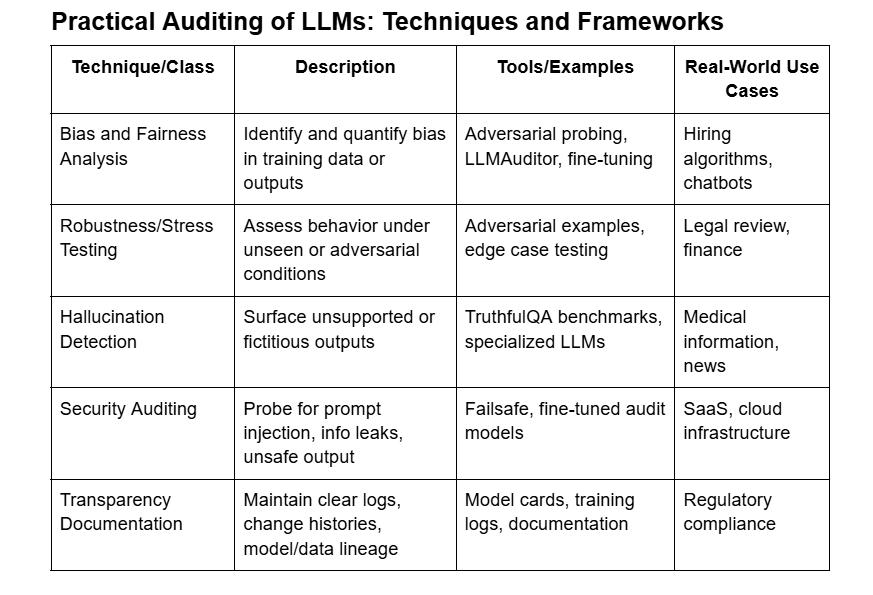
Several mature, community-supported tools are available to support LLM auditing. Their effective use depends on selecting the right tool for each phase of the auditing lifecycle:
Offer local interpretability for black-box models. These Python libraries work with tabular, text, and vision data and are highly useful in debugging individual predictions in high-stakes workflows.
Enable intuitive visualization of attention heads and token interactions in transformer-based models. Critical for diagnosing attention failures, understanding token salience, and demystifying sequence-to-sequence behavior.
Research-led frameworks designed for structured LLM testing. They enable black-box evaluation using probing questions, scenario-based testing, and cross-prompt consistency checks.
Frameworks like Model Cards for Model Reporting (by Google Research) and Datasheets for Datasets standardize transparency. These documentation formats capture key operational details: model purpose, training data scope, risk assessments, and known limitations. Regulatory frameworks such as the EU AI Act increasingly demand this level of traceability.
Each tool should be embedded into a pipeline, not used in isolation. For example, combine SHAP analysis with LLMAuditor probes to assess both feature influence and behavioral consistency under stress scenarios.
Even with robust tooling, explainability at scale faces systemic challenges. Addressing them early reduces audit fatigue and downstream risk.
Many post-hoc explanations look credible but don’t reflect the model’s true decision pathway. This can lead to false trust. Evaluators must distinguish between plausible sounding and mechanistically accurate explanations using ground-truth baselines or transparent surrogate models.
Explainability tools can inadvertently surface sensitive training data—especially when probing LLMs trained on large public datasets. Auditing frameworks must include PII redaction, access controls, and secure logging mechanisms to stay compliant with regulations like GDPR, HIPAA, or SOC 2.
Generating human-aligned, consistent explanations across thousands or millions of queries requires robust orchestration. Integrations with CI/CD pipelines, parallelized evaluation jobs, and dataset stratification techniques are necessary to avoid bottlenecks.
Auditable systems must account for jurisdictional laws (e.g., EU AI Act, CPRA), cultural norms, and historical biases in training data. Explainability is not only a technical task but an exercise in ethical responsibility engineering.
Without addressing these challenges head-on, LLM explainability risks becoming performative, appearing transparent without offering real accountability.
The path to demystifying LLMs and mitigating their black-box risks lies in a combination of post-hoc analysis, intrinsic model design, proactive security audits, and human feedback. Adopting practical explainability frameworks not only ensures regulatory compliance but also builds the trust and reliability mandated in the AI-driven future.
Whether you’re a security engineer, AI researcher, or enterprise stakeholder, embedding these concrete approaches into your LLM development and deployment pipeline will future-proof your operations and uphold the highest standards of responsible AI. Don’t let your AI remain a black box. Talk to we45 about auditing your LLMs for explainability, compliance, and enterprise security.
LLM explainability refers to the ability to understand and interpret how a large language model makes its decisions. It matters because models like GPT-4 often behave like black boxes, making it hard to trace the reasoning behind outputs. Without explainability, you risk deploying AI systems that are biased, insecure, or non-compliant with regulations in critical domains like healthcare, finance, or legal services.
Auditing an LLM involves a combination of post-hoc explanation tools (like LIME or SHAP), transparency documentation (such as model cards), intrinsic interpretability methods (like attention maps or chain-of-thought prompting), and human-in-the-loop validation. Audits typically test for hallucinations, bias, data leakage, and consistency using both automated and human feedback-driven approaches.
Post-hoc methods explain a model’s output after the fact. Tools like LIME and SHAP help identify which input features had the greatest influence on a given output. These methods don’t change the model itself but offer interpretable proxies to explain decisions. They are useful when the model’s internal mechanics are too complex or opaque to inspect directly.
Yes, to an extent. Intrinsic interpretability techniques design explainability into the model architecture or its behavior. Examples include attention visualization, chain-of-thought reasoning, and ReAct frameworks, which guide models to expose their reasoning steps as part of their output. These techniques improve transparency but may reduce performance or flexibility in certain use cases.
Human feedback adds contextual judgment to the auditing process. Domain experts can validate model outputs against real-world expectations and flag unclear or unsafe responses. This feedback can then be integrated into model updates through fine-tuning or reinforcement learning, helping align the model with ethical, regulatory, and organizational standards.
A plausible explanation sounds reasonable to a human but may not reflect how the model actually made its decision. A faithful explanation accurately mirrors the model’s internal reasoning. Tools that focus only on plausibility risk giving users a false sense of understanding. Audits must strive for explanations that are both understandable and mechanistically accurate.
Yes. Regulatory bodies are introducing transparency and accountability mandates for AI. The EU AI Act, GDPR, and US federal guidance increasingly require explainable decision-making, data lineage documentation, and evidence of bias testing. Auditable LLM pipelines that include explainability frameworks will be better positioned to meet these evolving standards.
Industries where decisions carry legal, financial, or life-altering consequences benefit the most. This includes: Healthcare (diagnostics, clinical recommendations), Finance (loan approvals, fraud detection), Legal (contract analysis, case summarization), Security and DevOps (incident response, threat analysis), Public sector (policy generation, citizen services). In these sectors, explainability is essential for trust, accountability, and regulatory alignment.
Detecting hallucinations involves both automated tools and human judgment. Techniques include: Using benchmarks like TruthfulQA to test factual accuracy, Applying LLMAuditor to probe for inconsistency across paraphrased prompts, Comparing outputs with ground truth datasets, Flagging unsupported claims for human review and scoring. Ongoing hallucination detection should be part of any enterprise LLM pipeline.
Key tools include: LIME/SHAP: For feature attribution in predictions, BertViz and exBERT: For attention visualization in transformers, LLMAuditor and AuditLLM: For black-box behavioral testing, Model Cards: For transparency and documentation, TruthfulQA: For evaluating hallucinations and factuality These tools help security teams, developers, and compliance auditors assess risk, monitor drift, and maintain model integrity over time.

















